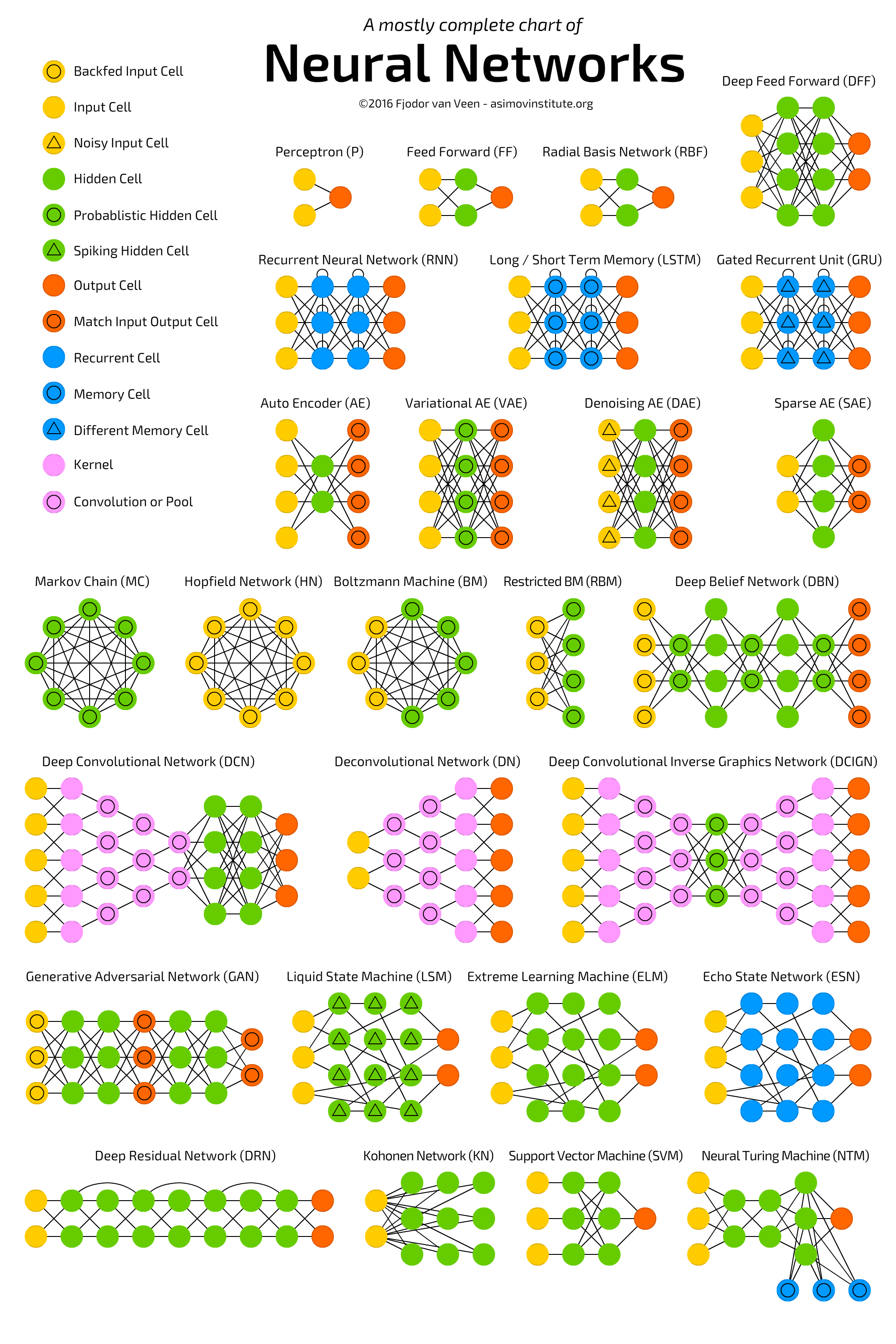
In de inleiding neurale netwerken van de sectie technieken heb je kennis gemaakt met de structuur van een kunstmatig neuraal netwerk (figuur 1) die is opengewerkt in figuur 2. Een neuraal netwerk bestaat uit een invoerlaag, verborgen lagen en een uitvoerlaag. De verborgen lagen en de uitvoerlaag zijn opgebouwd uit perceptrons (figuur 3), ook wel neuronen of knopen genoemd. Iedere percepton verwerkt de inkomende signalen tot een uitvoer door de inkomende signalen te wegen en het gewogen resultaat door te geven aan een ontvanger (volgende knoop of gebruiker). Tijdens het trainen van het netwerk wordt naar de meest passende wegingsfactoren gezocht. We gaan nu proberen het leerproces van een neuraal netwerk te verduidelijken en beginnen met het meest simpele netwerk waarmee we toch nog wat complexiteit kunnen duiden, een netwerk bestaande uit één perceptron met twee invoeren en één uitvoer. We gebruiken hier de trainingsvorm begeleid leren (=supervised learning).
De werking van een perceptron
Een perceptron volgt het "feed-forward"-model. Dit betekent dat inputs naar het neuron worden gestuurd, worden verwerkt en resulteren in een output, de stroom van informatie is dus in één richting. In het bovenstaande diagram betekent dit dat het netwerk (één neuron) van links naar rechts leest: inputs komen binnen, worden verwerkt en als output doorgegeven.
Laten we eens de verschillende stappen bekijken.
Het leren van de perceptron
Stel dat we een perceptron hebben met twee ingangen - laten we ze $x_{1}$ en $x_{2}$ noemen en als voorbeeld de volgende waarden geven:
$\mathbf{Invoer 2}: x_{2} = 4$
Bekijk nogmaals figuur 3. Elke invoer die naar een neuron wordt gestuurd, moet eerst worden gewogen, d.w.z. worden vermenigvuldigd met een bepaalde gewichtsfactor. Zoals boven al is gemeld, moeten juist die gewichtsfactoren door training worden bepaald. Bij het maken van een perceptron beginnen we meestal met het toewijzen van willekeurige gewichten. Laten we hier de invoer de volgende gewichten ($w_{1}$ en $w_{2}$) geven:
$\mathbf{Gewicht 2}: w_{2} = -1$
We nemen elke invoer en vermenigvuldigen deze met het bijbehorende gewicht:
$\mathbf{Gewicht 2} \cdot \mathbf{Invoer 2} = x_{2} \cdot w_{2} = 4 \cdot -1 = -4$
De gewogen invoer worden vervolgens opgeteld:
De uitvoer (output) van een perceptron wordt gegenereerd door de som uit de vorige stap door een activeringsfunctie te laten gaan. In het geval van een binaire uitvoer, is het de activeringsfunctie die bepaalt op basis van de waarde van de som of deze moet “vuren” of niet. Je kunt je een LED voorstellen die is aangesloten op het uitgangssignaal van de perceptron: als hij vuurt, gaat het licht aan; zo niet, dan blijft het uit.
Activeringsfuncties zijn er in verschillende vormen, simpele maar ook voor de leek moeilijker te begrijpen wiskundige functies. Voor ons eerste perceptron model houden we het zo simpel mogelijk. De activeringsfunctie die we hier kiezen is het teken van de waarde van de som. Met andere woorden, als de som een positief getal is, is de uitvoer 1, als het negatief is, is de uitvoer -1. In netwerken met meerdere lagen kan deze teken activeringsfunctie niet worden gebruikt om het netwerk te trainen (zie stap 4 in het trainingsproces dat verder op in dit hoofdstuk wordt behandeld). In de figuur hiernaast zie je behalve de teken functie nog de sigmoïde functie en de tangens hyperbolicus, deze activeringsfuncties gebruiken we in het volgende hoofdstuk.
Samengevat hebben we het volgende algoritme dat we hierna gaan programmeren.
Onderliggende lijn
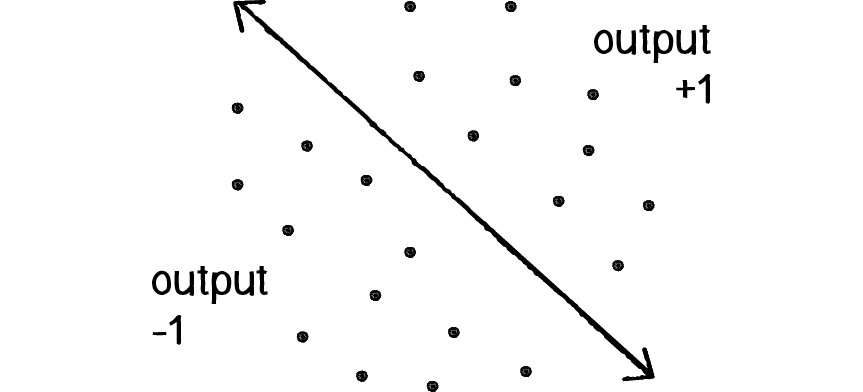
Figuur 4: Voorspel of een punt onder (output moet -1 zijn) of boven (output moet +1 zijn) de lijn ligt.
Figuur 6: de uitvoer van de perceptron: +1 als som groter dan 0, -1 als som kleiner dan 0. Vul een punt in (inclusief bias) en druk op de knop. Voor de uitleg van de grafiek zie de tekst.
Nu we het rekenproces van een perceptron begrijpen, gaan we deze met een herkenbaar voorbeeld in actie zetten. We hadden al gemeld dat neurale netwerken vaak worden gebruikt voor patroonherkenningstoepassingen, zoals gezichtsherkenning. Bij patroonherkenningstoepassingen wordt gezocht naar de klasse waartoe een patroon hoort. Zelfs met onze eenvoudige perceptron kunnen we de basisprincipes van classificatie demonstreren. In het volgende voorbeeld (figuur 4) gaan we, met slechts één perceptron, een scheidingslijn proberen te vinden tussen een regio -1 en +1. Om het netwerk te trainen, gebruiken we straks een verzameling punten met $x$- en $y$-coördinaten, in combinatie met de gewenste output per punt.
Je zou kunnen denken aan het zoeken van een kaarsrechte grens tussen twee grondsoorten. Aan één kant van de grens zit klei in de ondergrond, aan de andere kant zand. Er worden grondboringen verricht. Als er klei naar bovenkomt dan geven we dit monster de waarde 1, als er zand wordt aangeboord de waarde -1.
We beschouwen dus een lijn in een tweedimensionale ruimte (Zie figuur 4). Punten in die ruimte kunnen worden ingedeeld in een groep van punten die aan de ene kant van een lijn liggen en een groep aan de ander kant. Hoewel dit een ietwat dom voorbeeld is (we kunnen namelijk heel makkelijk bepalen of een punt onder of boven een lijn ligt), laat het voorbeeld zien hoe een perceptron getraind kan worden om punten aan de ene kant versus de andere te herkennen. Geven we het getrainde netwerk als invoer een $x$- en $y$-coördinaat dan moet het ons vertellen aan welke kant van de lijn dit punt ligt, zonder dat de vergelijking direct aan de perceptron wordt gegeven. Bovendien zal je zien dat in het trainingsproces de gewichten wel een heel speciale waarde krijgen.
We beginnen met het netwerk in figuur 3. Ofwel een neuraal netwerk met twee keer een invoer, één perceptron en één uitvoer gelijk aan de uitvoer van deze perceptron. De twee ingangen zijn de $x$- en $y$-coördinaten van een punt. Met behulp van een teken activeringsfunctie is de uitvoer -1, 0 of +1 — dat wil zeggen, de invoergegevens worden ingedeeld volgens het teken van de uitvoer. In figuur 4 kunnen we zien hoe elk punt zich onder de lijn (-1) of boven de lijn (+1) of op de lijn (0) bevindt.
Bias
We hebben met slechts twee invoeren wel een groot probleem. Als we het punt (0,0) aan dit netwerk voeren, dan is de gewogen som van de invoer altijd 0, want
$\mathbf{som} = x \cdot w_{1}+y \cdot w_{2} = 0 \cdot w_{1} + 0 \cdot w_{2}=0$.
Omdat de meeste lijnen niet door de oorsprong gaan, kan dit recept in het algemeen niet werken.
Om dit probleem te vermijden, heeft onze perceptron een derde input nodig, die wordt
de bias (=afwijking) input genoemd. Een bias-input heeft altijd de waarde 1 en wordt ook gewogen.
Hiernaast is in figuur 5 onze perceptron met de toegevoegde bias input weergegeven. De som wordt dan:
$\mathbf{som} = w_{0} + x \cdot w_{1}+y \cdot w_{2}$.
De som voor het punt (0,0) is dan:
$\mathbf{som} = w_{0} + 0 \cdot w_{1}+0 \cdot w_{2} = w_{0} $
ofwel het gewicht van de bias. Het gewicht $w_{0}$
bepaalt na training dus of (0,0) boven of onder de lijn ligt.
Nadat de som is berekend wordt in dit voorbeeld de uitvoer berekent met de teken activeringsfunctie.
$\mathbf{teken}(\mathbf{som})= 1$ als $som \gt 0$,
$\mathbf{teken}(\mathbf{som})= -1$ als $som \lt 0$ en
$\mathbf{teken}(\mathbf{som})= 0$ als $som = 0$
In de applet in figuur 6 kun je de uitvoer van een realisatie van onze perceptron laten uitrekenen, voor een punt $(x,y)$ vooraf gegaan door de input 1 voor de bias. Je kunt ook het punt verslepen om ervaren dat als je de lijn passeert het teken wisselt. Als je de knop "Maak nieuw perceptron" indrukt dan worden de gewichten $w_{0}, w_{1}, w_{2}$ opnieuw gekozen.
Waarom zie je in figuur 5 de rechte lijn? Deze rechte lijn is de weergave van de status van het perceptron. Deze status wordt gevormd door de waarden van de gewichten. Bekijk nogmaals de som
$$\mathbf{som} = w_{0} + x \cdot w_{1}+y \cdot w_{2}$$en laten we eens kijken naar het geval dat de som nul is (dus ook $teken(som) = 0$ ).
$$0=w_{0}+x \cdot w_{1}+y \cdot w_{2}$$-
antwoordDit is een vergelijking voor een rechte lijn. Herken je die niet in deze vorm kijk dan naar de volgende herleiding.
-
Herleiding$\begin{array}{rcl} 0 & = & w_{0} + x \cdot w_{1}+y \cdot w_{2} \Rightarrow \\ - y \cdot w_{2} & = & x \cdot w_{1}+ w_{0} \Rightarrow \\ y & = & \frac{w_{1}}{-w_{2}} \cdot x + \frac{w_{0}}{-w_{2}} \\ y & = & a \cdot x + b \end{array}$
Waarin $ a = \frac{w_{1}}{-w_{2}} $ en $ b = \frac{w_{0}}{-w_{2}} $
-
De gestippelde blauwe lijn in figuur 6 is dus de lijn die bij de perceptron hoort.
De code voor de perceptron in de applet vindt je onder de knop hieronder. Echter zonder de graphics. Wil je die ook pak dan dit document uit. In de code is het deel voor de perceptron gebundeld in een Javascript class Perceptron. Heb je nog nooit met Javascript classes gewerkt? In dat geval is onderstaand voorbeeld waarschijnlijk wel te volgen. Voor meer informatie over classes in Javascript kan je kijken op w3schools of je kan deze video bekijken.
-
Nieuwe code met Perceptron class
<html> <head> <script> const volgproces=false; // variabele wordt straks gebruikt om naar het console te schrijven var myPerceptron=null; // myPerceptron object wordt straks gemaakt // Het gebruik van objecten in javascript // wordt uitgelegd op https://www.w3schools.com/js/js_classes.asp// Definitie class Perceptron class Perceptron { /* * de methode constructor wordt aangeroepen als we straks * een Perceptron maken. * @param: n is het aantal inputs (inclusief de bias) die de perceptron krijgt * @param: f is de activeringsfunctie die de uitvoer bepaalt op basis van * de som van invoer keer gewichten f(som) */ constructor(n,f) { // Overal waar "this." voorstaat is een eigenschap // van een Perceptron object. // Sla het aantal knopen in een variabele op this.aantalInvoerKnopen = n; // Sla de activeringsfunctie in een variabele op ; this.activeringsfunctie = f; // We maken nu een eerste gok voor de gewichten voor de Perceptron this.gewichten=[]; // maak random gewichten voor het perceptron for(var i=0;i<n;i++) { // Trek een toevalsgetal tussen 0 en 1. Door deze // met 2 te vermenigvuldigen en er 1 van af // te trekken wordt het dus een toevalsgetal tussen -1 en 1 this.gewichten[i]=2*Math.random()-1; } } /* * geefDoor is de feed-forward functie. De invoer [1,x1,...,xn] * wordt verwerkt tot de uitvoer */ geefDoor(invoer) { var som =0; var i,uitvoer; // bepaal de som van de gewogen invoer for(i=0;i<this.aantalInvoerKnopen;i++) { som += invoer[i] * this.gewichten[i]; } if(volgproces) console.log("De som van de gewogen invoer is "+ som); // verwerk de som met de activeringsfunctie return uitvoer = this.activeringsfunctie(som); } } //einde definitie Perceptron// De vind lijn app code /* * functie maakPerceptron maakt een globaal Perceptron object myPerceptron * als die nog niet bestaat met n invoer knopen */ function maakPerceptron(n,f) { if(myPerceptron==null) myPerceptron = new Perceptron(n,f); } /* * functie waarLigtPunt vraagt aan de perceptron in welk gebied het punt ligt * @param punt: [1, x-coördinaat , y - coördinaat ] */ function waarLigtPunt(punt) { // Maak zo nodig de perceptron met de lengte van het punt en de teken functie if(myPerceptron==null) { maakPerceptron(punt.length, Math.sign ); } document.getElementById("uitvoer").innerHTML= "De output voor het punt " + punt + " is " + myPerceptron.geefDoor(punt); } // einde vind lijn app code</script> </head> <body> <button onclick="waarLigtPunt([1, 12 , 4])">Bereken de perceptron voor [1, 12 , 4] ofwel voor ht punt (x,y)=(12,4)</button> <p id="uitvoer"></p> </body> </html>
Trainen van het netwerk
We hebben nu een perceptron die een voorspelling kan maken over de ligging van een punt $(x,y)$ ten opzichte vaneen lijn. Dit doet de perceptron door middel van de uitvoer functie geefDoor. Maar eigenlijk hebben we hier nog niks aan, de gewichten zijn namelijk willekeurig gekozen en toegewezen. We moeten het netwerk dus gaan trainen om het een goede voorspeller te laten zijn. In het trainingsproces is het de bedoeling dat het netwerk zelf tot een acceptabel resultaat komt. Afhankelijk van de complexiteit van een netwerk en de data zal dit trainen meer of minder moeite en dus ook tijd kosten. Daarover later meer.
Zoals eerder beloofd gebruiken we hier begeleid leren (supervised learning). We bieden de perceptron punten aan waarvan we weten wat de uitvoer is. Laten we nu eens kijken naar de essentiële stappen in het trainingsproces.
Stappen in het trainingsproces
- Geef het netwerk invoer waarvoor het antwoord bekend is.
- Vraag het netwerk om een antwoord bij die invoer.
- Bereken de fout. (Was het antwoord van het netwerk goed of fout?)
- Als er een fout is, pas dan de gewichten binnen het netwerk aan.
- Ga terug naar stap 1 als er nog meer te trainen valt.
We passen begeleid leren toe. De trainer moet het netwerk (de leerling) van correcte voorbeelden voorzien, zodat het kan leren wat goed en fout is. Dit doen we in stap 1. Bijvoorbeeld bij punt (2,3) hoort uitvoer 1 en bij punt (0, 0) hoort uitvoer 0.
Stap 2 hebben we hierboven al behandeld, invoer [1, 2, 3] met de teken functie wordt omgezet in -1, 0 of 1 afhankelijk van de gewichten van de perceptron. Stel je geeft het punt (2, 3) aan de perceptron. Als de perceptron dan een uitvoerwaarde berekent die niet gelijk is aan 1, dan heeft de perceptron een fout gemaakt. Dit moeten we proberen te corrigeren zodat de perceptron de volgende keer hopelijk wel het goede antwoord geeft. Hiervoor moeten we eerst de fout berekenen.
Berekenen fout
De fout van een perceptron (of meer algemeen: netwerk) kan worden gedefinieerd als het verschil tussen het gewenste antwoord en zijn voorspelling.
In het geval van onze perceptron, met de teken functie als activeringsfunctie, heeft de uitvoer slechts drie mogelijke waarden: +1, 0, of -1. De mogelijke combinaties en de bijbehorende fouten staan in de tabel onder de knop. Zo is bijvoorbeeld bij een gewenste uitkomst 1 en voorspelling -1 de fout gelijk aan $1 - (-1) = 2$ en andersom bij een gewenste uitkomst -1 en voorspelling 1 is de fout gelijk aan $ (-1) - 1 = -2$
-
Foutentabel
Gewenst 1 1 1 0 0 0 -1 -1 -1 Voorspeld -1 0 1 -1 0 1 -1 0 1 fout 2 1 0 1 0 -1 0 -1 -2
Aanpassen gewichten
Nu we de fout hebben berekend moeten we de gewichten aanpassen. De fout is de bepalende factor in hoe de gewichten van de perceptron moeten worden aangepast. Wat we voor een bepaald gewicht willen berekenen, is de verandering in dat gewicht, vaak $\Delta \mathbf{gewicht}$ genoemd (of "delta"-gewicht, waarbij delta de Griekse letter $\Delta$ is). Op basis van deze verandering bereken we een nieuw gewicht.
$\mathbf{nieuw}\,\mathbf{gewicht} = \mathbf{gewicht} + \Delta \mathbf{gewicht}$
$\Delta \mathbf{gewicht}$ wordt berekend door de fout te vermenigvuldigen met de invoer.
$\Delta \mathbf{gewicht} = \mathbf{fout}\,\cdot\,\mathbf{invoer}$.
De waarden van de nieuwe gewichten voor $w_0$, voor de bias, $w_1$, voor input x, en $w_2$, voor input y, worden dus bepaald op basis van waarde van de fout en de waarden van de invoer. Waarom werkt onze methode? We komen daar snel op terug.
Helaas zijn we er met bovenstaande regel nog niet helemaal. Omdat onze fout de waarden $-2,-1,0,1,2$ kan aannemen, kan het zijn dat $\Delta \mathbf{gewicht}$ te groot is en we over ons doel heen springen. We moeten het daarom mogelijk maken de snelheid van veranderen te kunnen sturen. We gebruiken daarvoor een factor $\mathbf{leersnelheid}$, zodat
$\Delta \mathbf{gewicht} = \mathbf{leersnelheid}\,\cdot\,\mathbf{fout}\,\cdot\,\mathbf{invoer}$.
Met deze laatste aanpassing is onze functie compleet en kunnen we het gaan toepassen in het leerproces van de perceptron.
De laatste stap, stap 5, van het trainingsproces is recursief (het proces wordt nog een keer aangeroepen). Als de gewichten zijn aangepast kan er worden gekeken of de voorspellingen van de perceptron voor de trainingsdata overeenkomen met de uitvoer van de trainingsdata, zo niet dan moet er verder worden getraind.
Overdenking trainingsstrategie
We hebben nu de regel om de gewichten van de perceptron te veranderen en leggen straks, met behulp van een wiskundige redevoering, uit waarom de regel werkt. Voor we dit doen proberen een beeld bij het trainen te schetsen.
In het begeleid leren wordt het netwerk gevoed met trainingsvoorbeelden waarbij bij een gegeven invoer de uitvoer bekend is. Deze uitvoer is in de ideale situatie correct, maar bij experimentele gegevens is dat hopelijk bij benadering waar. B.v. voor de quickdraw applicatie tekent iemand een kat. De intentie is een kat, maar de tekening lijkt eigenlijk net iets meer op een hond dan op een kat. Het plaatje gaat dan als kat de training van de applicatie in terwijl het eigenlijk als hond geclassificeerd had moeten worden. Als er teveel fouten aanwezig zijn dan kan er ook met AI geen waardevolle conclusies uit de dataset worden getrokken. Voorbeelden van andere fouten die kunnen optreden zijn bijvoorbeeld meetfouten in de invoer en of meetfouten in de uitvoer. Fouten in de trainingsdataset noemt men experimentele bias.
In het begeleid leren wordt het netwerk gevoed met trainingsvoorbeelden waarbij we vooronderstellen dat bij bekende invoer een bekende uitvoer aanwezig is. De manier van trainen in begeleid leren kan verschillen afhankelijk van de zekerheid van deze vooronderstellingen. Als zowel de invoer als de uitvoer volledig vast ligt kan men b.v. per trainingsvoorbeeld net zolang trainen tot het voorbeeld juist wordt voorspeld, dit is meestal efficiënter.
Als er echter foute of moeilijk te onderscheiden waarnemingen in de trainingsvoorbeelden zitten dan is dit geen goede strategie. Er moet een mogelijkheid voor het netwerk zijn om aan het trainingsvoorbeeld te kunnen "ontsnappen". Doe je dat niet dan kan zo'n fout invoer,uitvoer paar te zwaar meewegen in de berekeningen. Hierdoor kan het eindresultaat nooit helemaal correct voorspellingen doen, gezien het voorzien is van incorrecte of op elkaar gelijkende voorbeelden. Bij wijze van spreken kan zo’n fout paar niet in de grijze massa verdwijnen, maar is dan een dwingeland die met fake news zijn zin wil doordrijven. Als er fouten in de trainingsdata zijn (experimentele bias), dan zou het wiskundig het beste zijn om, vergelijkbaar met b.v. lineaire regressie, alle fouten die in de voorspellingen van het netwerk samen nemen en dan pas een aanpassing aan de gewichten van de perceptron te doen. Bij een grote trainingsdataset is dat echter weer lastig uit te voeren. Daarom wordt meestal gekozen voor het één keer aanpassen per datapunt, dit vervolgens voor alle datapunten te doen. Vervolgens kan deze hele reeks weer worden herhaald tot een aanvaardbaar niveau van de voorspellingen is bereikt.
Wiskundige onderbouwing waarom de regel voor de perceptron werkt.
Nu is het toch echt tijd om duidelijk te maken waarom de regel
$\mathbf{nieuw}\,\mathbf{gewicht} = \mathbf{gewicht} + \mathbf{leersnelheid}\,\cdot\,\mathbf{fout}\,\cdot\,\mathbf{invoer}$
werkt.
Er zijn meerdere manieren om dit te doen. Wij bekijken een manier die weinig wiskundige kennis vergt, namelijk vanuit de fouten tabel. Omdat de kans heel klein is dat we een punt precies op de lijn vinden, bekijken we alleen de situatie dat de fout -2, 0 of 2 is.
Als de fout 0 is dan is $\mathbf{leersnelheid}\,\cdot\,\mathbf{fout}\,\cdot\,\mathbf{invoer}=0$ en veranderen de gewichten niet.<
Bekijk nu de situatie fout= -2. Dan is de gewenste voorspelling voor een punt $[1,x,y]$ gelijk aan -1 en de voorspelling van de perceptron voor dit punt gelijk aan 1. De voorspelling kregen we van de perceptron uit de som:
$\mathbf{som}=w_{0}+w_{1}x+w_{2}y$.
Deze is in dit geval positief $(\gt 0)$. Om de som negatief $(\lt 0)$ te laten worden, ofwel de gewenste voorspelling te kunnen bereiken, moet de som in de volgende stap, dus met de nieuwe gewichten op zijn minst kleiner worden voordat som = 0 gepasseerd kan worden. De nieuwe gewichten bij fout = -2 zijn:
$[ w_{0}-2 \cdot \mathrm{leersnelheid}\,,\,w_{1}-2\cdot\mathrm{leersnelheid} \cdot x\,,\,w_{2}-2 \cdot\mathrm{leersnelheid} \cdot y]$.
De nieuwe som is dan:
$\mathrm{som}=w_{0}-2 \cdot \mathrm{leersnelheid}+(w_{1}-2\cdot\mathrm{leersnelheid} \cdot x)x+(w_{2}-2*\mathrm{leersnelheid} \cdot y)y $
Werken we de haakjes weg dan krijgen we iets mooiers:
$\mathrm{som}=w_{0}+w_{1}x+w_{2}y-2\cdot\mathrm{leersnelheid}-2\cdot\mathrm{leersnelheid} \cdot x^{2}-2\cdot\mathrm{leersnelheid} \cdot y^{2}$
En nog iets mooiers als we de leersnelheid buiten haakjes halen:
$\mathrm{som}=w_{0}+w_{1}x+w_{2}y-2\cdot\mathrm{leersnelheid}\cdot(1+ x^{2}+ y^{2})$
De oude som was $\mathrm{som}=w_{0}+w_{1}x+w_{2}y$, ofwel het eerste deel van de nieuwe som en die was groter dan nul. Omdat de leersnelheid positief is en ook $1+ x^{2}+ y^{2}$ positief is, wordt dus een positief getal $2 \cdot \mathrm{leersnelheid} \cdot (1+ x^{2}+ y^{2})$ van iets positiefs afgetrokken. De nieuwe som is dus echt kleiner. De regel voor de verandering van de gewichten werkt dus in ieder geval voor fout= -2.
Aan de slag met trainen
Voor de wiskundige onderbouwing hebben we de manier van trainen overdacht. In dit deel bekijken we deze overdenkingen met een simpele trainer alleen geschikt voor de perceptron. Deze trainer is aanwezig in de applet in figuur 7. In de applet trainen we onze perceptron met de bedoeling een juiste voorspelling voor de lijn (rood gestippeld in de figuur) $y=2x-1 \Leftrightarrow 1 - 2x + y =0$ te bereiken.
De gestreepte blauwe lijn is de representatie van de perceptron. Het doel van de trainer is dus dat de blauwe lijn op de rode lijn komt te liggen. De trainer zelf weet echter niets van de ligging van de rode lijn, behalve dat het een rechte lijn moet zijn.
De invoer (punten $(x,y)$) wordt bij toeval gekozen en de gewenste uitvoer wordt precies bepaald door de ligging ten opzichte van de lijn. Ofwel er zijn geen meetfouten in de trainingsdata. De trainer kan alleen leren van de aangeboden punten.
Discussie
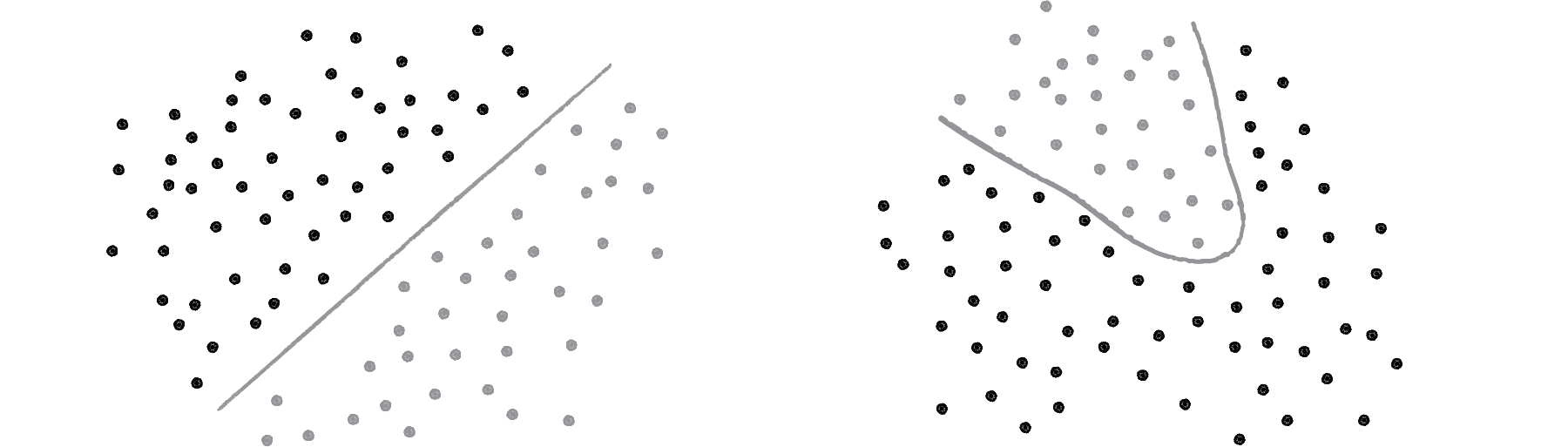
figuur 8: Het probleem links kan wel met één perceptron worden opgelost, er is één grenslijn. Het probleem rechts kan niet met één perceptron worden opgelost, de grens is niet lineair. Bron:Nature of code
In het laatste stuk van dit hoofdstuk vatten we de mogelijkheden, onmogelijkheden en eigenschappen van de perceptron, het simpelste neurale netwerk, samen. Als eerste moet je beseffen dat een enkele perceptron ( en dus ook iedere knoop in een ingewikkelder neuraal netwerk) slechts één lineair probleem kan oplossen (zie figuur 8).
Een lineair probleem is daarin niet alleen een lijn. Met bijvoorbeeld drie invoeren en de bias heeft het preceptron 4 gewichten die samen de vergelijking $w_{0} + w_{1} \cdot x + w_{2} \cdot y + w_{3} \cdot z = 0$ als grens vormen. Dit is de vergelijking van een plat vlak. In de wiskunde staat lineair voor termen waarin er geen machten, producten of andere functies van termen staan. Zo zijn bijvoorbeeld $1 + x^2 + y = 0$ , $2 + x \cdot y + 3 y = 0$ en $1 + log(x) + \sin(y) = 0$ geen lineaire vergelijkingen.
Neurale netwerken zijn te trainen om o.a. handschriften, geluiden en te gezichten te herkennen. Dit zijn zeker geen lineaire structuren. Gelukkig kun je dit soort structuren weer opknippen in lijnstukjes of platte figuurtjes die dan wel weer door één preceptron te leren zijn. Er moeten dan natuurlijk wel meerdere perceptrons in het netwerk aanwezig zijn. Hoe complex zo'n netwerk moet zijn is niet altijd makkelijk te bepalen. In het volgende hoofdstuk gaan we hier dieper op in. Op de afbeelding hieronder, die je ook al gezien in het hoofdstuk technieken, zie je dat er heel veel typen neurale netwerken zijn. Ieder type heeft een eigen toepassingsgebied. Klik hier of op de afbeelding als je er meer over wilt weten.
In het trainen van ons simpele netwerk heb je al gezien dat er heel veel trainingspunten nodig zijn. Dit is in het algemeen zo. Het leren van een netwerk kost veel tijd en energie. In ons simpele netwerk waren er slechts drie gewichten die moeten worden aangepast. Zetten we er nog een zelfde perceptron naast dan worden dat er al zes. In een netwerk van zes knopen met twee inputs en een bias zijn dat er al $6 \cdot 3 = 18$. Om al die gewichten voldoende nauwkeurig te schatten zijn heel veel datapunten nodig.